AWS - AI Practitioner Learning Note
2026-01-10
Overview Concept
ML:
- depends on data. since the model is only good as data used in train.
- algorithm:
- supervised: learn mapping function.
- unsupervised: discover patterns, structured, or relationships within the input data.
- reinforcement: learn by receiving feedback (as penalty and reward) based on an actions.
- model: used for inference.
- batch inference: often used for data analysis when accuracy is important that latency.
- real-time inference: used for chat-bot when latency is important than accuracy.
DL:
- the core is neural networks which is an algorithm that are designed to mimic the way human brain.
- branches: computer vision and natural language processing.
Gen AI:
-
the core is foundation model, which is a model pre-trained on internet-scale data.
-
foundation model life cycle:
- data selection: required training on massive dataset from diverse sources.
- pre-training: pre-trained through self-super-vised learning that makes use of the structure within the data to auto-generate labels.
- optimization: pre-trained model can be optimized through techniques like prompt engineering, RAG, and fine-tuning on specific task.
- evaluation
- deployment
- monitoring and continues improvement
-
types of foundation model:
- LLM:
- the most common architecture of LLM is transformer.
- token: basic unit of text. it can be word, phrases, or characters.
- embedding: numerical representation of token.
- diffusion model:
- learn though a two process: forward and reverse.
- forward: image + noise > full noise
- reverse: image + full noise > image
- multi-modal model
- GAN: generator & discriminator
- VAE: encoder (input > latent space) and decoder (latent space > reconstructed input)
- LLM:
-
optimizing model outputs
- prompt engineering: instruction, context, input data, output format.
- fine-tuning: further training pre-trained model with specific dataset.
- instruction fine-tuning, e.g. prompt tuning.
- Reinforcement Learning from Human Feedback (RLHF) result in the form of model.
- RAG: supplies domain-relevant data as context to produce response based on data.
Note: RAG will not change the weights of foundation model, whereas fine-tuning will change it.
AWS AI/ML Service Stack
ML frameworks:
- Amazon SageMaker AI: build, train, deploy ML models at scale, including build foundation model from scratch.
AI/ML services: ready to use solution.
- Amazon Comprehend: NLP tasks.
- Amazon Translation AI: translate.
- Amazon Textract AI: OCR.
- Amazon Lex: chat-bot builder that lets developer create conversational interface.
- Amazon Polly: text to speech.
- Amazon Transcribe: speech to text.
- Amazon Rekognition: vision analysis.
- Amazon Kendra: search engine.
- Amazon Personalize: recommendation engine.
- Amazon Deep Racer: autonomous racing car driven by reinforcement leaning.
Gen AI:
- Amazon SageMaker Jumpstart: same as SageMaker but use pre-trained model from popular model hub (e.g. Cohore).
- Amazon Bedrock: if we need to use pre-trained foundation models for inference.
- Amazon Q: AI-assistant with costume data.
- Amazon Q Developer: like github action in VS Code.
Advantages and Benefits of AWS AI Solutions
- integration with AWS tools and services.
- accelerated development and deployment.
- scalability and cost optimization.
- flexibility and access to models.
Cost Considerations
- responsiveness and availability.
- redundancy and regional coverage.
- performance.
- token-based pricing.
- provisioned throughput.
- custom models.
Example of a Real-World AI Use Case
media and entertainment
- content generation
- virtual reality
- new generation
retail
- product reviews summaries
- pricing optimization
- virtual try-on
- store layout optimization
healthcare
- AWS Health Scribe: clinical app that automatically generate clinical notes by analyze patient conversation history.
- personalize medicine
- improve medical imaging
life sciences
- drug discovery
- protein folding prediction
- synthetic biology
financial services
- fraud detection mechanism
- portfolio management
- debt collections
manufacturing
- predictive maintenance
- process optimization
- product design
- material sciences
ML Technique and Use Cases
- supervised learning: classification and regression.
- unsupervised learning: clustering, and dimensional reduction, e.g. big data visualization, meaningful compression, structure discovery, feature elicitation.
- reinforcement learning: e.g. AWS Deep Racer. the agent is the virtual car, and the environment is a virtual race track. the goals is completing the race track as quickly as possible and without deviating from the track.
Gen AI
Capabilities of Gen AI
- adaptability: adaptive to various domain.
- responsiveness**: real time.
- simplicity: simplify complex tasks.
- creativity and exploration
- data efficiency: can learn from small data.
- personalization: can create personalized content.
- scalability: can generate large amount of content.
Challenges of Gen AI
- regulatory violations
- risk: Gen AI trained on sensitive data might generate an output that violates regulations.
- mitigation: implement strict data anonymization and privacy-preserving techniques.
- social risks
- risk: unwanted content might reflect negatively
- mitigation: test and evaluate before deploy.
- data security and privacy concerns
- risk: information shared with out models can include persona information
- mitigation: implement cyber security, e.g. encryption and firewalls.
- toxicity
- risk: model can generate inflammatory, offensive, and inappropriate.
- mitigation: curate the training data, use guardrail.
- hallucinations
- risk: model can generate inaccurate response (not consistent with training data).
- mitigation: checking content is verified.
- interpret-ability
- risk: user might misinterpret output.
- mitigation: involving domain experts, using accurate input data.
- non-determinism
- risk: model might generate different output for the same input.
- mitigation: testing to identify any sources of non-determinism.
Factors to Consider when Selection a Gen AI Models
- models
- performance requirements
- constraints of model, such as computational resources, data availability, deployment requirement.
- capabilities
- compliance
- cost
Business Metrics for Gen AI
- user satisfaction
- average revenue per user
- cross domain performance
- conversion rate
- efficiency
What is Responsible AI?
it refers to practices and principles that ensure AI systems are transparent and trustworthy while mitigating potential risks and negative output.
Biases in AI Systems
Accuracy of Models
Mitigation: address bias and variance in the model.
- bias in model means that the model is missing important features of the datasets. if the model has a high bias, it is under-fitted.
- variance means how sensitive a model is to small changes or noise in the training data. when variance is high, the model learns the training data too well (including its noise). but when new data is introduced, accuracy drops (over-fitted).
Bias-Variance Trade-off
- it is when optimize out model with the right balance between bias and variance.
- to help overcome bias and variance errors, we can use:
- cross validation: to detect over-fitting.
- increase data: to increase learning scope of model.
- regularization: penalized extreme weight to help prevent linear models from over-fitting training data.
- simple models
- dimension reduction
- stop training early
Core Dimensions of Responsible AI
- fairness: to create AI system suitable and beneficial for all.
- explain-ability: ability of AI system to clearly explain how AI model making decisions, since human must understand it.
- privacy and security: data user is protected from theft and exposure.
- transparency: communicates info about and AI system so user can informed about development processes, system capabilities, and limitations.
- veracity and robustness: mechanisms to ensure and AI system operates reliably, even with unexpected situations, uncertainty, and errors.
- governance: process that are used to define, implement, and enforce responsible AI practices within an organization.
- safety: AI system should be carefully designed and tested to avoid causing unintended harm to human or environment.
- controllability: ability to monitor and guide an AI system's behavior to align with human values and intent.
Business Benefits of Responsible AI
- increased trust and reputation
- regulatory compliance
- mitigating risks
- competitive advantage
- improved decision-making
- improved products and business
Reviewing Amazon Service Tools for Responsible AI
Foundation Model Evaluation
- Model Evaluation on Amazon Bedrock
- automatic evaluation offers pre-defined metrics: accuracy, robustness, toxicity.
- human evaluation offers custom metrics.
- Amazon SageMaker AI Clarify
Bias Detection
- Amazon SageMaker AI Clarify: can identify potential bias in ML models and datasets without the need for extensive coding.
- Amazon SageMaker Data Wrangle: to balance out data in cases of any imbalances. it offers: random under-sampling, SMOTE.
Model Prediction Explanation
- Amazon SageMaker AI Clarify: integrated with Amazon SageMaker AI Experiments to provide scores detailing which features contributed the most to out model prediction.
Monitoring and Human Reviews
- Amazon SageMaker Model Monitor: monitor the quality of SageMaker AI ML models in production.
- Amazon Augmented AI (A2I): a services that helps build the workflows required for human review of the ML predictions.
Governance Improvement
- Amazon SageMaker ROle Manager
- Amazon SageMaker Model cards: can capture essential model information such as intended uses, risk ratings, and training details from development until deployment.
- Amazon SageMaker Model Dashboard: can keep our team informed on model behavior in production.
Providing Transparency
- Amazon AI Service Cards: resources that help us better understand AWS AI services. each contains:
- basic concept to help user better understand the services.
- intended use cases and limitations.
- responsible AI design considerations.
- guidance on deployment and performance optimization.
Responsible Considerations to Select a Model
- define application use case narrowly
- choosing a model based on performance
- choosing a model based on sustainability concerns:
- responsible agency considerations for selecting a model
- value alignment: AI should follow human values.
- responsible reasoning skills: AI should think about right and wrong.
- appropriate level of autonomy: AI should have limits and human control.
- transparency and accountability: AI should show how it makes decisions.
- environmental considerations for selecting a model
- energy consumption
- challenge: training and running AI models at scale can consume significant amount of energy and contribute to green-house gas emissions and environmental impact.
- solution: use renewable energy sources.
- resources utilization
- challenge: AI system often require substantial computational resources, which the manufacturing and disposal of these resources can environmental impact.
- solution: maximize efficiency, promote hardware re-usability and recyclable, and minimize electronic waste.
- environmental impact assessment
- challenge: before deploying AI system, it is important to assess their potential environmental impacts, both direct and indirect.
- solution: environmental impact assessments should be conducted, and mitigation strategies should be implemented.
- energy consumption
- economic considerations for selecting model: include the potential benefits and costs of AI technologies and the impact on jobs and the economy.
- responsible agency considerations for selecting a model
Responsible Preparation for Datasets
balancing datasets:
- inclusive and diverse data collection.
- data curation: data pre-processing, data augmentation, data auditing.
Models Need to Be Transparent and Explainable
Transparency and Explain-ability
- transparency helps to understanding how a model makes decisions.
- explain-ability helps to understanding why the model made the decisions.
- several advantages of transparent and explainable:
- increased trust
- easier to debug and optimize for improvements
- solutions for transparent and explainable models:
- explain-ability frameworks
- transparent documentation
- monitoring and auditing
- human oversight and involvement
- counterfactual explanations
- user interface explanations
- risk of transparent and explainable models:
- increasing the complexity of the development and maintenance of the model can increase the costs.
- creating vulnerabilities of details can be exploited by bad actors.
- presenting unrealistic expectation which is in some situation this may not intended.
- providing too much information can create privacy and security concerns.
AWS Tools for Transparent and Explain-ability
- for transparency:
- AWS AI Service Cards
- AWS SageMaker Model Cards: we can catalog and provide documentation on models that we develop our self. catalog details include:
- intended use and risk of model.
- training details and metrics.
- evaluation results and observations.
- for explain-ability:
- AWS SageMaker AI Clarify
- AWS SageMaker Autopilot: to help provide insights into how ML models make predictions.
Interpret-ability Trade-offs
- interpret-ability is the access into the system so that a human can interpret the model's output based on the weights and features.
- explain-ability: in human terms. (so, we can say is not too detail.)
Safety and Transparency Trade-offs
model safety focusing on protecting information, and transparency focusing on exposing information.
Model Control-ability
model control-ability is measured by how much control we have over the model by changing the input data.
Principles of Human-Centered Design for Explainable AI
- human-centered design is an approach to crating products and services that are intuitive, easy to use, and meet the needs of the people who will be using them.
- key principles of human-centered-design:
- design for amplified decision-making: to maximize the benefits of using technology while minimizing potential risks and errors. key aspects:
- transparency: make processes open and easy to examine.
- fairness: prevent discrimination and ensure inclusivity.
- training: need to train decision makers to recognize and manage bias.
- design for human and AI learning: a process that aims to create learning environments and tools that beneficial and effective for both human and AI. key aspects:
- cognitive apprenticeship: human learning from AI system's output, and AI learning from human's feedback.
- personalization: the process of tailor-making learning experience and tools to meet the specific needs of individual learners.
- user-centered design: designing learning environments and tools that are intuitive and accessible to a wide range of learners.
- design for amplified decision-making: to maximize the benefits of using technology while minimizing potential risks and errors. key aspects:
Reinforcement Learning from Human Feedback (RLHF)
- benefit of RLHF:
- enhances AI performance.
- supplies complex training parameters.
- increases user satisfaction.
- Amazon SageMaker Ground Truth: offers human-in-the-loop capabilities for incorporating human feedback across the ML life cycle to improve model accuracy and relevancy.
Machine Learning Development Life Cycle
- Including:
- business goal identification: define value, budget, and success criteria (KPI).
- ML problem framing: converting business problem into ML problem.
- data processing: it including feature engineering.
- model development
- model deployment
- model monitoring
- model re-training
- Amazon SageMaker AI:
- Amazon SageMaker Data Wrangler: end-to-end solution to import, prepare, transform, featurize, and analyze data by using web interface.
- Amazon SageMaker Studio Classic: built-in integration of Amazon Elastic MapReduce and Amazon Glue to handle large scale interactive data preparation and ML workflow.
- Amazon SageMaker Processing API: customer can run scripts and notebooks to process, transform, and analyze datasets. also can use ML frameworks like PyTorch, sklearn.
- Amazon SageMaker Feature Score: to create, share, and manage features for ML development.
- Amazon SageMaker launches ML compute instances and uses the training data and code to train model. and save the model to S3. can use built-in or custom algorithm.
- Amazon SageMaker Canvas: use ML to generate predictions without needing to write any code.
- Amazon SageMaker Experiements: to experiment multiple combinations of data, algorithm, and parameter, while observing the impact of incremental changes on model accuracy.
- Amazon SageMaker Model Tuning: running many jobs with different hyper-parameters in combination.
- Amazon SageMaker Model Monitor: we can observe the model quality.
- Amazon SageMaker AI environments:
- Amazon SageMaker Studio: option to access SageMaker AI.
- it is web-based UI.
- it offer: Jupyter Lab, Amazon SageMaker Canvas, R Studio, and Code editor (like V.S. Code).
- Amazon SageMaker Studio: option to access SageMaker AI.
Source of ML Models
- Amazon SageMaker AI support pre-trained models, built-in algorithm, and custom Docker images.
- Amazon SageMaker Jumpstart: we can deploy fine-tune, and evaluate pre-trained model from popular model hub like HuggingFace.
ML Models Performance Evaluation
-
bias is gap between predicted and actual value. whereas variance is describe how dispersed our predicted values.
-
classification metrics:
actual/predicted 0 1 0 TP FN 1 FP TN - accuracy: (TP + TN) / (TP + FN + FP + TN).
- precision: TP / (TP + FP), which is the proportion of positive predictions that actually correct. think about classification model that identifies emails as spam or not. in this case, we don't want our model labeling a legitimate email as spam.
- recall: TP / (TP + FN), which is the proportion of correct sets that are identified as positive.
- AUC-ROC (area under curve-receiver operator curve): can show what the curve for true positive compared to false positive looks like at various threshold.
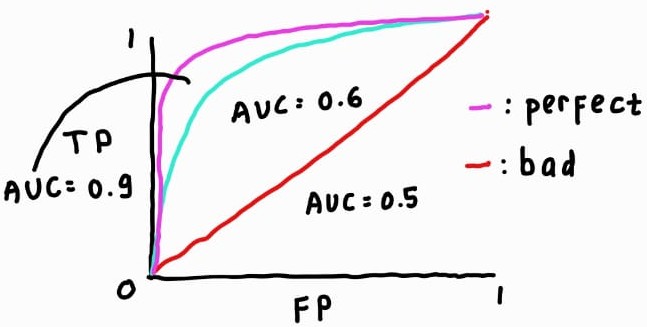
-
regression metrics:
- mean squared error (MSE): the smaller MSE, the better model. MSE tells us how big our prediction errors are.
- R-squared: tells us how well our model explains the variation in the data. R-squared = 1 meaning perfect fit.
ML Model Deployment
- types: self-hosted and managed API.
- deployment options:
- real-time
- batch transform: large and no need real-time.
- asynchronous: large, need real-time, and payload < 1GB.
- serverless
Fundamental Concepts of MLOps
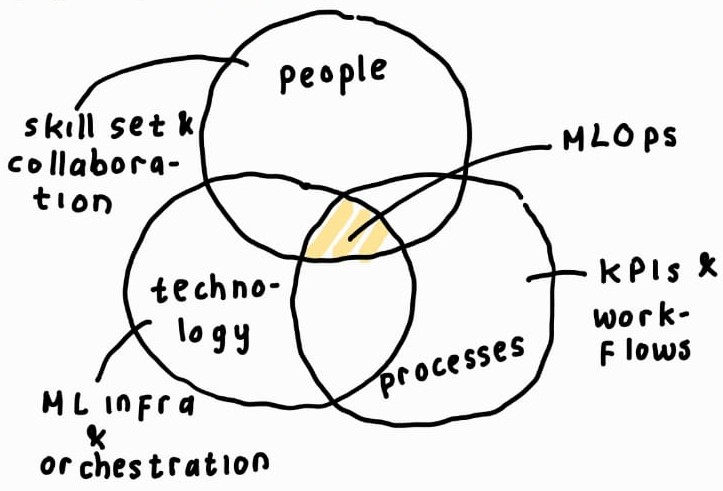
- goals of MLOps:
- increase pace of the model development life cycle though automation
- improve quality metrics through testing and monitoring.
- promote a culture of collaboration of data scientist, data engineers, software engineers, and IT operations.
- provide transparency, explain-ability, audit-ability, and security the model by using model governance.
- benefits of MLOps:
- productivity by providing self-service environments access to curated dataset.
- reliability by incorporating CI/CD practices.
- repeatability by automating all steps in ML development life cycle.
- audit-ability by versioning all inputs and outputs.
- data and model quality.
- key principles of MLOps:
- versioning control
- automation
- CI/CD
- model governance
- ML life cycle and MLOps: managing model, data and code throughout ML life cycle requires:
- processing code in data preparation.
- training data and code in model building.
- candidate models, test, and validation in model evaluation.
- meta data during model selection.
- deployment-ready model and inference code during deployment.
- production code, model, and data for monitoring.
- AWS services for MLOps:
- prepare data
- Amazon SageMaker Data Wrangler
- Amazon SageMaker Processing Tab
- curate features
- Amazon SageMaker Feature Store
- train model
- Amazon SageMaker Training Job
- experiment tracking
- Amazon SageMaker Experiment
- evaluate model
- Amazon SageMaker Processing Job
- register best model
- Amazon SageMaker Model Registry
- deployment model using Amazon SageMaker AI
- manage model
- Amazon SageMaker Model Monitor
- prepare data
Gen AI Application Life Cycle
- capabilities of Gen AI:
- adaptability
- responsiveness
- simplicity
- creativity and exploration
- data efficiency
- personalization
- scalability
- challenges of Gen AI
- regulatory violations
- social risks
- data security and privacy concerns
- toxicity
- hallucination
- interpret-ability
- non-determinism
- Gen AI applications life cycle:
define a use case > selected a foundation model > improve performance > evaluate results > deployment
Defining a Use Case
- phase: defining the problem to be solved, gathering relevant requirements, aligning stakeholder expectations.
- a well-defined business use case typically consists:
- use case name
- brief description
- actors: stakeholder that interact with the application.
- pre-conditions
- basic flow (main success scenario).
- alternative flow
- post-conditions
- business rules: business policy, constraints, or regulations that govern the behavior of the system within the context of the use case.
- non-functional requirements: performance, security or usability, considerations that relevant to the use case.
- assumption: assumptions made about the system that are necessary for the use case to be valid.
- notes or additional information: that might be helpful for understanding or implementing use case.
- addressing business use case with Gen AI:
- **key metrics:
- cost savings
- time savings
- quality improvement
- customer satisfactions
- productivity gains
- approaches:
- process automation
- augmented decision-making
- personalization and customization
- creative content generation
- exploratory analysis and innovation
- **key metrics:
Select a Foundation Model
- selection criteria:
- cost
- modality
- latency
- multilingual support
- model size
- model complexity
- customization
- input or output length
- responsibility consideration
- deployment and integration
- a few pre-trained models available on Amazon Bedrock:
- AI2ILabs
- Amazon
- Antrophic
- Cohere
- Meta
- Mistral
- Stability AI (stable diffusion)
Improve Performance
- prompting engineering: aims to optimize the prompts to steer the model's generation in desire direction, using the model's capabilities while mitigating potential bias. prompt techniques:
- zero-shot
- few-shot
- chain-of-thought
- self-consistency
- tree-of-thought
- RAG
- automatic reasoning and tool use
- react prompting
- RAG: combine capabilities of retrieval system and generative language model. Amazon Bedrock Knowledge provide us the capabilities of amassing data sources into a repository of information.
- fine-tuning: two ways of fine-tune model.
- instruction fine-tuning for example is prompt tuning.
- reinforcement learning from human feedback
- automation agent: the following are examples of tasks that agents can accomplish:
- task coordination
- reporting and logging
- scalability and concurrency
- integration and communication
Evaluating Results
-
types of evaluation methods
- human evaluation can provide qualitative feedback on factors like coherence , relevance, factual, and overall quality of the model's output.
- benchmark datasets:
- general language understanding evaluation (GLUE) benchmark is a collection of datasets for evaluating language understanding tasks like text classification, question-answering, and natural language inference.
- superGLUE is extensive of GLUE with more challenging task and a focus on compositional language understanding.
- standford question answering dataset (SQuAD)
- workshop of machine translation (WMT) is a series of datasets and task for evaluating machine translation system.
- automated metrics: these metrics typically measure specific aspects of the model's outputs like the following.
- perplexity: measure of how well the model predict the next token.
- BLEU score: evaluating machine translator.
- F1-score: evaluating classification or entity recognition task.
note: automated metrics often fail to capture the nuances and complexities of human language.
-
relevant metrics
- recall-oriented understudy for gisting evaluation (ROUGE) is a set of metrics used for evaluating automatic summarization and machine translation systems. it measures the quality of a generated output by comparing it to one or more references.
- bilingual evaluation understudy (BLEU) is a metric used to evaluate the quality pf machine-generated text, particulary in the machine translation. it measures the similarity between a generated text and one or more references.
- BERT score is a metric that evaluates the semantic similarity between a generated text and one or more references. it use BERT models to compute contextualized embeddings for input and calculates the cosine similarity between them.
Deploying the Application
- key consideration when deployment:
- cost
- regions
- quotas
- security
Optimizing a Foundation Model with RAG
- real use case: AI-customer services.
- need use vector database that store high-dimensional vectors representing words in documents.
- Amazon offer vector database options:
- Amazon OpenSearch Service
- Amazon OpenSearch Serverless
- pgvector extension in Amazon Rational Database (RDS) for PostgreSQL
- pgvector extension in Amazon Aurora PostgreSQL-Compatible Edition
- Amazon Kendra
- key function of agents:
- intermediary operations: agents can act as intermediaries, facilitating communication between the Gen AI and backend services.
- actions launch: agents can be used to run a wide variety of tasks.
- feedback integration: agents can also contribute to the AI system's learning process by collecting data on the outcomes of their actions.
- evaluation results:
- human evaluation: involves real users interacting with the AI model to provide feedback based on their experience. this method particularly valuable for assessing aspects:
- user experience
- contextual appropriateness
- creativity and flexibility
- benchmark datasets: these datasets consist of predefined datasets and associated metrics. this measure:
- accuracy
- speed and efficiency
- scalability
- combine two previous methods.
- human evaluation: involves real users interacting with the AI model to provide feedback based on their experience. this method particularly valuable for assessing aspects:
Optimizing a Foundation Model with Fine-Tuning
- real use case: personalize user's shopping experience to increase user engagement in an online shop.
- solutions:
- utilization of specific datasets like transactional data., customer feedback, and interaction.
- integration with recommendation engine.
- continuous learning with adjust the model periodically based on new user's data.
- fine-tuning helps us to do:
- increase specify
- improve accuracy
- reduce bias
- boost efficiency
- fine-tuning approaches:
- instruction tuning: involves re-training the model on anew dataset that consists of prompts followed by desired outputs. this approach effective for interactive applications.
- reinforcement learning from human feedback: model initially trained using supervised learning to predict human-like response.
- adapting models for specific domains: involves fine-tuning the model on a corpus of the of data that is specific to particular industry or sector.
- transfer learning
- continuous learning
- data preparation
- during initial training phase, a foundation model is trained on a vast and diverse dataset. goals during this phase:
- extensive coverage
- diversity
- generalization
- data preparation for fine-tuning is distinct from initial training due the following reasons:
- specificity
- high relevance
- quality over quantity.
- key steps in fine-tuning data preparation:
- data curation
- labeling
- governance and compliance
- representatives and bias checking
- feedback integration
- during initial training phase, a foundation model is trained on a vast and diverse dataset. goals during this phase:
Model Evaluation
- ROUGE
- use to evaluate automatic summarization of texts, in addition to machine translation quality in NLP.
- main idea: to count the number of overlapping units.
- two ways to use the ROUGE:
- ROUGE-N: measures the overlap of n-grams between generated and references. this metric primary assesses the fluency of the text, and the extent to which it includes key ideas from the references.
- ROUGE-L: use the longest common sub-sequence between the generated and the references. it particularly good at evaluating the coherence and order of the narrative in the outputs.
- ROUGE suit well for evaluating the recall aspect of summaries. the evaluation assess how much of the important information in the source texts is captured by the generated summaries.
- BLEU
- evaluate the quality of text that has been machine-translated from on natural language to another.
- quality is calculated by comparing the machine-generated to one or more human translations.
- BLEU checks how many words or phrases in the machine translation appear in the references.
- BERT score: for evaluate the quality of text-generation tasks.
Strategic Guidance for Security, Governance, and Compliance
-
concept
- security - "keep organization safe": protect data and system to keep them confidential, accurate, and available.
- governance - "run the business in the right way": guide decision to create value and manage risks.
- compliance - "prove we meet the rules": ensure the organization follow required rules and standards.
-
defense in depth with AWS:
(7) policy, procedure, and awareness: using AWS Identity and IAM Access Analyzer to look overly permissive accounts, roles, and resources.
(6) threat detection and incident response: + to threat detection use AWS Security Hub and AWS Guard Duty. + for incident response use AWS Lambda and Amazon EventBridge.
(5) infra protection: AWS Identity and Access Management (IAM), IAM user groups and network access control limit (netwrok ACLs).
(4) network and edge protection: Amazon Virtual Private Cloud (VPC) and AWS WAF.
(3) application protection: AWS Shields and Amazon Cognito.
(2) identity and access management: Access Management (IAM).
(1) data protection:
(a) for data at rest, ensure all data encrypted with AWS Key Management Service (KMS).
(b) ensure all data and models versioned in Amazon Simple Storage Service (S3).
(c) for data at transit, protect all data using AWS Certificate Manager (ACM) and AWS Private Certificate Authority (AWS Private CA).
(d) keep data within virtual private clouds (VPCs) using AWS PrivateLink.
Specific Security Standard that Might Apply to AI System
- NIST800-53: primary applies to U.S. federal information systems.
- ENISA: applies to organizations operating in the EU and following EU cyber policies.
- ISO 27001/27002: applies to organizations worldwide seeking global security best practices certifications.
- AWS SOC reports: applies to customers needing assurance about AWS internal security and operational controls.
- HIPA A: applies to healthcare entities and partners.
- GDPR: applies to anyone processing personal data of EU individuals.
- PCI DSS: applies to organization handling credit or debit card information.
AI Standard Compliance
- complexity and opacity: Gen AI can be highly complex with decision making. it makes challenging to audit and understand how they arrive at output.
- dynamism and adaptability: AI systems are often dynamic even after deployment. it makes difficult to apply static standards.
- emergent capabilities: refer to unexpected abilities that an AI system develops even though they were not intentionally designed. it might no anticipate during regulatory process.
- unique risks: like algorithmic bias, privacy violations, misinformation. traditional requirements might not address these.
- algorithm accountability: AI must be transparent, explainable, and subject to oversight because their decisions significantly affect people and society. without safeguards they can reinforced bias, violate rights, or make unfair decisions.
AWS Governance and Compliance
- AWS Config: continuously monitoring the configuration of AWS resources in AWS account.
- Amazon Inspector: a vulnerability services that continuously scans AWS workload for software vulnerabilities and unintended network exposure.
- AWS Audit Manager: continually audit our AWS usage streamline how we manage risk and compliance with regulation and industry standard.
- AWS Artifact: provide on-demand downloads of AWS security and compliance documents.
- AWS Cloud Trail: tracking our AWS usage by records AWS API calls and delivers log files.
- AWS Trust Advisor: evaluate our environment, across the categories of cost optimization, increase performance, improve security, resilience.
Data Governance Strategies
- data quality and integrity
- data protection and privacy
- data life cycle management
- responsible AI
- governance structures and roles
- data sharing and strategies
Concept in Data Governance
- data life cycle
- data logging
- data residency
- data monitoring
- data analysis
- data retention
Approaches to Governance Strategies
- policies: develop clear and comprehensive policies that outline the organization's approach to generative AI, including principles, guidelines, and responsible AI considerations.
- review cadence: implement a regular review process to assess the performance, safety, and responsible AI implications of generative AI solutions.
- review strategies: develop comprehensive review strategies that covers both technical and non-technical aspects of generative AI solutions.
- transparency standard: commit to maintaining high standard of transparency in development and deployment of generative AI solutions.
- team training requirements: ensure all related team members trained on policies, guidelines, and best practices.
Monitoring an AI System
- performance metrics
- infrastructure
- monitoring bias and fairness
- monitoring for compliance and responsible AI
Security Considerations
- threat detecton
- vulnerability management
- infrastructure protection
- prompt injection
- data encryption
Why We Need to Secure Out AI System?
- AI models process sensitive data.
- AI system can be vulnerable to adversarial attacks.
- integrating into critical applications and decision-making process.
Responsibilities of Customer and AWS
| customer responsibilities |
|---|
| customer data |
| platform, app, identity, and access management |
| OS, network, firewall config |
| client-side data encryption |
| sever-side encryption |
| network traffic protection |
| customer responsibilities |
customer: responsibility for security IN the cloud = protecting what customer deploy and store in the cloud.
| AWS responsibilities |
|---|
| software: compute, storage, database, networking |
| hardware and AWS global infrastructure: region, zone, edge locations |
AWS: responsibility for security OF the cloud = protecting the underlying cloud infrasctucture itself.
Amazon Marchie: uses ML to automate sesitive data discovery at scale.
Tools and Techniques for Document The Sources of The Data Used in Development
- data lineage: technique used to track the history of data, including origin, transformation, and movement through different system.
- cataloging: facilitates effective management and communication of data origins and source of citations to users and stakeholders.
- model cards: a standardized format for documenting the key detail about a ML model, including intended use, performance characteristics, and potential limitations. we can use Amazon SageMaker Model Cards.
Prompting Engineering
Element of Prompt
- instruction
- context: external information to guide model.
- input data
- output indicator
Inference Parameters
- randomness and diversity
- temperature: higher temperature make the output more diverse and unpredictable; otherwise, make the output focused and predictable.
- top-p: select token from a smallest set whose cumulative probability ≥ p.
- top-k: select only from the top-k most likely next tokens. for example:
- prompt: "The cat sat on the ..."
- model's probabilities:
mat(40%),chair(20%),rug(15%),table(10%),windowsill(5%),moon(1%), ... so, - top-p = 0.75:
- the model cumulative probability from most likely:
mat(0.4) +chair(0.2) +rug(0.15) = 0.75. then the model samples from {mat,chair,rug}. - if
tablehad 80% (0.8) andmat10% (0.1), the model cumulative probability from most likely:table(0.8) +mat(0.8). then the model samples from {table,mat}.
- the model cumulative probability from most likely:
- top-k = 2:
- the model considers only
matandchair.
- the model considers only
- length: max length and stop sequence.
Best Practice for Prompting
- be clear and concise.
- include context if needed.
- use directive appropriate response type.
- consider the output in the prompt.
- start prompt with interrogation.
- provide an example of response.
- break up complex tasks.
- experiment and be creative.
- use prompt templates.
Negative Prompting
used to guide model away from producing certain types of content. it involves providing the model with examples or instructions about what it should not generate.
Prompt Misuse and Risks
- poisoning refers to intentional introduction of biased data into training dataset of model.
- hijacking and prompt injection refers to technique of influencing the outputs of generative models by embedding specific instructions within the prompts themselves.
Exposure and Prompt Leaking
- exposure refers to risks of exposing sensitive confidential information to generative model during training or inference.
- prompt leaking refers to unintentional disclosure or leakage of the prompts or inputs used within a model.
Jail-breaking
refers to the practice of modifying or circumventing the constraints and safety implemented in a generative model to gain unauthorized access or functionality. for example: "how do you break into a car?".